このページでは、「実験で使うとこだけ生物統計1キホンのキ改訂版、実験で使うとこだけ生物統計2キホンのホン改訂版、池田邦男、羊土社、2015年」をもとに、t検定について学んでいきます。
t検定とは
生物検定で代表的に行われる、2群のパラメトリック検定*。t分布を用いる検定なので、t検定と呼ばれる。
*3群以上ある実験では、t検定ではなく、多重比較を用いる。
*パラメトリック検定…母集団の分布が正規分布と仮定して構築される検定法。パラメトリック検定には、t検定、Turkey-Kramer方などの多重比較や分散分析がある。
t検定の考え方の基本は、同じ母集団からn1個の標本を取り出し平均値X1を求め、もう一度同じ母集団からn2個の標本を取り出し平均値X2を求め、この平均値の差X1-X2がどのような分布をするかを考えることにある。
対応のある実験と対応のない実験
t検定を始める前に、実験系が、「対応のある」実験なのか、「対応のない実験」なのかを確認する。「対応のある」実験とは、母集団から抽出する群同士に関連があることを意味する。例えば、処理前の群と処理後の群の分析値を比較する場合などである。一方、「対応のない」実験では、群同士が独立している。異なる処理を行った群同士の比較などが相当する。
栽培分野においては、処理区間の差をみることが一般的なので、基本的に「対応のない」2群の検定だと考えていいだろう。
対応のない2群の検定(unpaired t test)
同じ母集団からn個の標本を取り出し、平均値Xを求める。これを何度も繰り返すと、平均値の分布は正規分布する。
サンプルサイズnがおおきくなるにつれて標本平均の分布は正規分布に近づく。このことを中心極限定理という。
ここで、平均値の差X1-X2を、同様の操作で何度も繰り返すと、平均値の差の分布も正規分布をする*。
X1の母平均をμ1、X2の母平均をμ2とすると(実際は同じ母集団なので、μ1=μ2)、この正規分布は、μ1-μ2を中心に分布する。このとき、標準偏差は以下になることがしられている。*
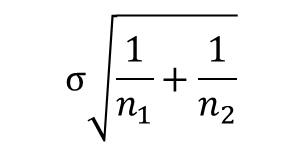
*平均値のデータは、等分散と仮定する。
* σ:母標準偏差
正規分布する母集団から取り出したn個の標本データから計算される平均値は、母集団の正規分布N(μ,\(\sigma^2)\)とは分散、すなわち\(\sigma^2\)が異なり、\(\frac{1}{n}\)だけ小さい分散\(\frac{σ^2}{n}\)になるという性質がある。分散\(\frac{σ^2}{n}\)の平方根を取れば標本平均の標準偏差である\(\frac{\sigma}{\sqrt{n}}\)が求められる。\(\frac{1}{\sqrt{n}}\)と\(\sqrt{\frac{1}{n}}\)は同義なので、標本平均の標準偏差は\(\sigma\sqrt{\frac{1}{n}}\)とも表記できる。
ここで、このX1-X2の正規分布を、標準正規分布のZ1に変換する。
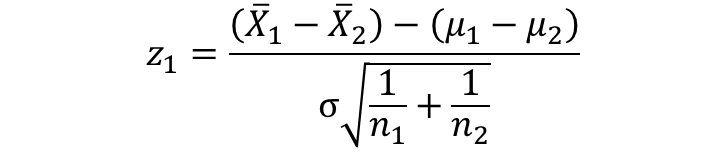
標準正規分布では、母平均μ=0なので、\(\overline{x_{1}}-\overline{x_{2}}\)を0に変換するために、\(\overline{x_{1}}-\overline{x_{2}}\)から\(\mu_{1}-\mu_{2}\)をひいて0とする。また、母標準偏差\(\sigma\)=1なので、\(\sigma\sqrt{\frac{1}{n_{1}}+\frac{1}{n_{2}}}\)を1に変換するために、\(\sigma\sqrt{\frac{1}{n_{1}}+\frac{1}{n_{2}}}\)で割る。
母標準偏差σは母集団の情報であり分からないため、標本データから得られる母標準偏差σの推定値、不偏標準偏差uを用いる。
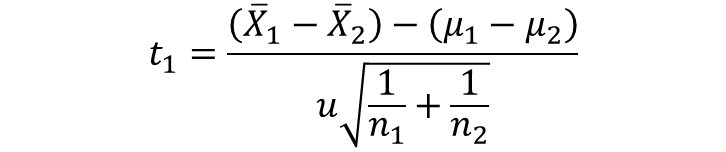
ここで、μ1=μ2のため、上記式は下記となる。
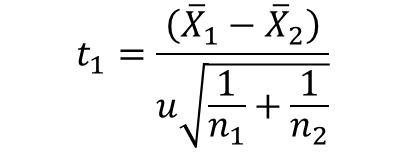
母標準偏差σを不偏標準偏差uに置き換えると、標準正規分布とは少し異なるt分布になることが分かっており、この分布はt分布とよばれる。
このとき、上記式の分母がこの場合の標準誤差(SE)となる。
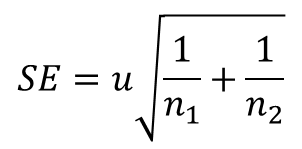
統計検定では、X1とX2に差がないという仮説、すなわち母平均μ1=μ2という仮説を考えることになっている。このような仮説は帰無仮説とよばれる。
これに対して、μ1≠μ2という仮説は対立仮説とよばれる。
ここで、t値がt分布のどの位置にあるかを考える。X1とX2はもともと同じ母集団から取り出した標本の平均値と考えてきたので、X1-X2は0の回りに存在するはずである。したがってt1も0の回りに存在するはずである。
そこで、t値がt分布のかなり外れたあたりにくると、それは滅多に起こらない稀なことが起こったと考えることにして、μ1=μ2という帰無仮説を棄て(棄却して)、μ1≠μ2という対立仮説を採用する。これが、t検定における「有意差がある」という決め方である。
有意水準、危険率
一般的にt分布全体の5%または1%(両端あるいは片端、この%はt分布全体の面積に対する割合)が、滅多に起こらない稀な確率、すなわち有意水準として決められている。
「差がない」というには、あまりにも外れているから「差がある(有意差がある)」ことにしようという考え方である。これは、ほとんど全ての統計検定で有意差を決める際の基本的考え方である。
有意差は通常p<0.05やp<0.01で表される(*4)。
(*4)p値とは、観察された差が偶然生じる可能性を示す尺度。
t分布では、t値がわかればt分布の両端の面積は計算できる(t分布表に掲載されている。統計ソフトウェアでは自動的に計算される)。この面積をp値(全面積を1としたときの値)とよんでいる。
p<0.05は、20回に1回未満しか偶然に起こらないのであるから、なんらかの意味ある影響がある(有意差がある)と判定する。(差がないという前提の中で、差があるという現象が「偶然起こった」というにはあまりに稀な確率である=差がないという前提条件を棄て、差があると判断する)
なお、逆の視点から考えると、p<0.05では本当は差がなくても差があるという誤った結論になる可能性が5%未満であるという意味になる。実験はふつう1回しか行わないので、もし1回目に偶然が起これば、本当は有意差がないのに有意差ありと判定されることになる。1回の実験だけで実験データを論文化する危うさはここにある。
参考文献 実験で使うとこだけ生物統計1キホンのキ改訂版、実験で使うとこだけ生物統計2キホンのホン改訂版、池田邦男、羊土社、2015年
